Data Extractor Diffbot Wants To Turn The Web Into The Semantic Web
Startup nabs $10 million to launch its massive structured database that “knows” about products, news, profiles, comments and other web content.

From the Diffbot website
Many companies grab web content, analyze it and return stats on sentiment, product mentions and the like.
But startup Diffbot says it takes a different approach that can automatically sort the web into human-like categories of knowledge.
And today the Palo Alto, California-based company is announcing a new Series A round of $10 million in investment funding, which will back the expansion within a few weeks of its newest tool — a massive structured database called the Global Index — from a closed beta phase to general availability.
Founded in 2008, the company specializes in automatically extracting the unstructured content on web pages, categorizing it using artificial intelligence, computer vision and natural language processing, and then storing it by data type in a structured database.
It may be obvious to a human that, for example, an image on a retailer’s page is of a pair of shoes, this number on the page is the price and this abbreviation is the color. But unless the page has been marked up in XML or other semantic marking to identify which info is a color, a crawler and the processing engine won’t be able to store “BR” as the color for this pair of sneakers or “$100” as its price.
Semantic Web Content
Diffbot grabs the info at the URL, renders the page inside its system and employs computer vision to visually analyze the page’s structure.
Essentially, Diffbot is creating semantic Web content — that is, information that is characterized by its meaning — even though the page hasn’t been formatted that way. It can automatically detect product, article, image, video, author, date, discussion threads, pricing info, product IDs like SKU, brand, video thumbnail and other categories.
VP of product John Davi told me it can also scan images and find, for instance, all photos of Barack Obama wearing a blue tie.
Each page element — headline, photo, SKU and so on — is stored separately and made available for searching. Here, for instance, is a Diffbot-generated breakdown of a story I posted yesterday:
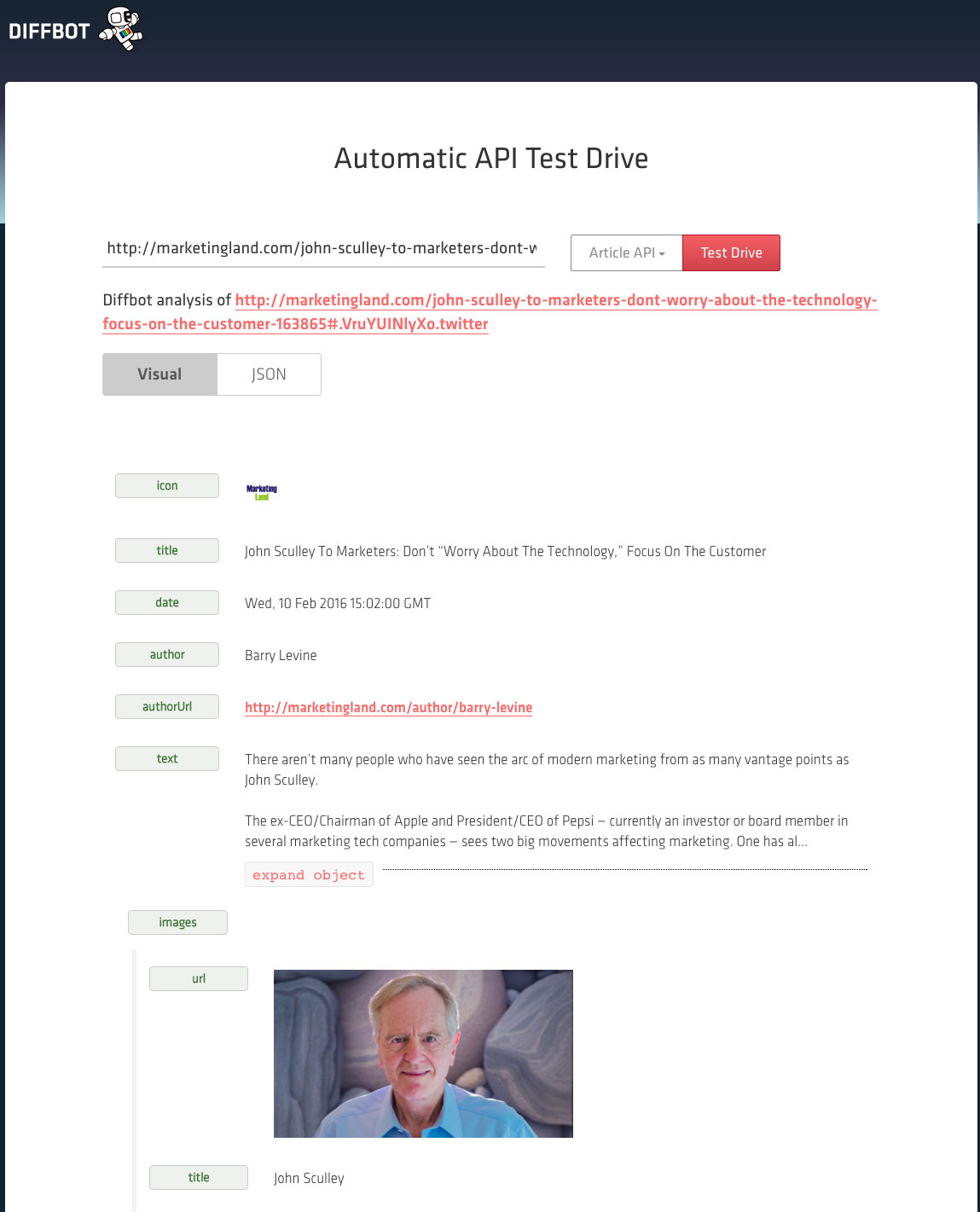
Diffbot has been providing what Davi called a “web reading robot” in support of specific applications. Instapaper, for instance, utilizes Diffbot to capture articles, identify and store its elements (title, story, images and so on), and then make them available for offline reading later.
Similarly, Cisco has used its service to monitor forums to automatically capture, store and categorize comments about products and those of its competitors. Other customers include Microsoft’s Bing, Duck Duck Go, eBay and Adobe.
“It’s A Big Web Out There”
Davi said the company has been beta testing the Global Index since last summer. One test, for example, ranked travel brands according to the kinds of sentiments found on forums.
The idea of the Index is to build a huge structured database of sorted, web-based knowledge that developers can tap for marketing or other uses, or for applications. Eventually, he indicated, the company would like to make it available via a dashboard as a searchable knowledge base of web content for marketers and other non-technical users.
In many ways, the Global Index is comparable to Google’s Knowledge Graph, which also categorizes info on the web into usable and related knowledge. But, Davi said, the Google effort is based on Wikipedia, the database from its Metaweb acquisition, several other sources and human efforts. It’s also available only through Google’s search engine, while the Global Index will shortly be open to the public.
Diffbot says its index, which has been autonomously spidering only since the summer, already contains more than 1.2 billion objects, where an object is an assembly of data representing some useful piece of knowledge, like a product. Google’s Knowledge Graph, it says, has only recently passed a billion objects after some years.
The initial focus of the Index has been on news and information, but the company has a much bigger ambition: to categorize most of the business-valuable information on the web. That will take at least three to five years, Davi acknowledges.
“It’s a big web out there,” he pointed out.
Contributing authors are invited to create content for MarTech and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. MarTech is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.
Related stories
About the author