What does the future hold for genAI? The Gartner Hype Cycle
GenAI may be at the peak of the hype cycle now, but how will it avoid a plunge into the trough of disillusionment?
Spy on Any Website
It’s no surprise to anyone that generative AI and the foundational models that support it are currently to be found at the very summit of what Gartner calls “the peak of inflated expectations” in the latest iteration of the “Gartner Hype Cycle for Artificial Intelligence.” That means they’re teetering on the precipice that could plummet them into the “trough of disillusionment.”
We spoke with Afraz Jaffri, director analyst at Gartner with a focus on analytics, data science and AI about how we should interpret the situation. The interview has been edited for length and clarity.
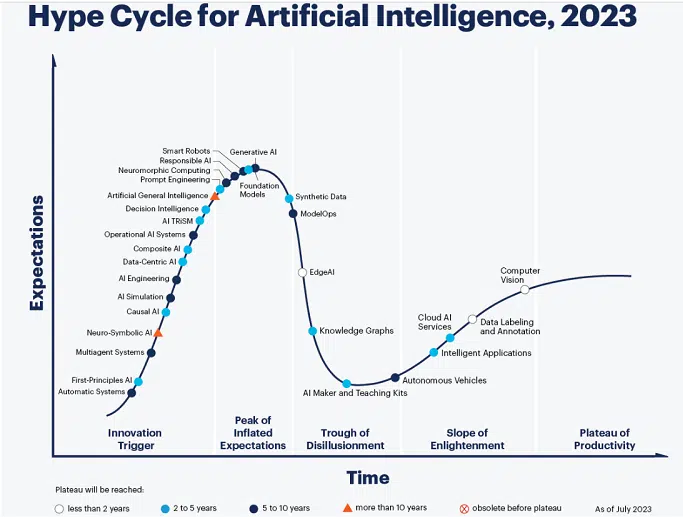
Q: You’re projecting that it will take two to five years for the foundation models, five to 10 years for generative AI to reach the “plateau of productivity.” What is that based on?
A: This is around where we can see real adoption, not just among a select number of enterprises, which will probably be done a lot quicker, but amongst all the levels of organizations — predominantly in the form of packaged applications. Every piece of software will have some kind of generative AI functionality in it, but the actual productivity gains from those features will take longer to be understood. It’s a race for everyone to ship a generative AI product or feature within their software; in all of those cases, the benefits will take longer to come to fruition and be measured as well.
Foundation models cover a wide spectrum; not just the large language models but image and video models. That’s why the time to plateau will be longer. It’s a bucket of all kinds of models.
Dig deeper: Why we care about AI in marketing
Q: It’s possible to imagine things that could be very disruptive to generative AI. One is regulation — there are real concerns, especially in Europe, about large language models scraping personal data. The other relates to copyright. Have you taken those kinds of possible disruptions into account here?
A: Yes, they are part of the thinking. The first issue is actually the trust aspect. Regardless of external regulations, there’s still a fundamental feel that it’s very hard to control the models’ outputs and to guarantee the outputs are actually correct. That’s a big obstacle. As you mentioned, there’s also the cloud around regulations. If in Europe the models come under significant regulation, they might not even be available; we have already seen ChatGPT removed there for some time. If the big enterprises do see that it’s too much trouble to comply, they may simply withdraw their services from that region.
There’s also the legal side. These models are based on, as you said, data that includes copyrighted data scraped from the web. If the providers of that data start to ask for appropriate redemption, that has an impact on the future level of usage of these models as well. Then there’s the security side. How secure can you make these models against things like attacks. Definitely some headwinds here to navigate.
Q: We hear a lot about the “human-in-the-loop.” Before releasing anything created by generative AI to an audience, you need to have human review and approval. But one of the benefits of genAI is the speed and scale of its creativity. How can humans keep up?
A: The speed and the scale is there to be used by humans doing the things they need to do. It’s there to help people who, say, need to go through 10 documents to get an answer to something; now they can do it in one minute. Because of the trust issue, those are the most valuable types of tasks to use a language model for.
Q: If responsible AI is five to 10 years out from the plateau, looks like you’re predicting a bumpy ride.
A: The regulatory world and other systems are unknown; and even when they do become formalized and known there will be different regulations for different geographies. The innate nature of these models is that they do have a tendency to not be safe. Being able to control that is going to take time to learn. How do you check that a model is going to be safe? How do you audit a model for compliance? For security? Best practices are hard to come by; every organization is taking its own approach. Forget about generative AI, other AI models, those that have been used by organizations for some time, are still making mistakes, are still exhibiting biases.
Q: How should people prepare for the imminent trough of disillusionment?
A: Organizations will follow different trajectories in their experience of generative AI, so it doesn’t necessarily mean an organization needs to fall into the trough. It generally happens when expectations are not managed. If you start out by looking at some targeted use cases, some targeted pieces of implementation, and you have good metrics for success, and also investments in data management and organization; good governance, good policies; if you combine all that with a practical narrative about what the models can do, then you’ve controlled the hype and you’re less likely to fall into the trough.
Q: Would you say the AI hype cycle is running faster than others you’ve looked at?
A: The AI hype cycle does tend to have a skew towards innovations that do move quicker across the curve — and they tend to be more impactful in what they can do as well. At the moment, it’s front and center for funding initiatives, for VCs. It’s such a focal area, in the research space as well. A lot of these things come out of academia, which is very active in this space.
Q: Finally, AGI, or artifical general intelligence (AI that replicates human intelligence). You have that as coming in ten years or more. Are you hedging your bets because it might not be possible at all?
A: Yes. We do have a marker which is “obsolete before plateau.” There is an argument to say it’s never actually going to happen, but we’re saying it’s greater than 10 years because there are so many different interpretations of what AGI actually is. Lots of respected researchers are saying we’re on the path that will get us to AGI, but many more breakthroughs and innovations are needed to see what the path actually looks like. We think it’s something further away than many people believe.
Dig deeper: Discover cutting-edge martech solutions for free – online next week!
Contributing authors are invited to create content for MarTech and are chosen for their expertise and contribution to the martech community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. MarTech is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.
Kim Davis is currently editor at large at MarTech. Born in London, but a New Yorker for almost three decades, Kim started covering enterprise software ten years ago. His experience encompasses SaaS for the enterprise, digital- ad data-driven urban planning, and applications of SaaS, digital technology, and data in the marketing space. He first wrote about marketing technology as editor of Haymarket’s The Hub, a dedicated marketing tech website, which subsequently became a channel on the established direct marketing brand DMN. Kim joined DMN proper in 2016, as a senior editor, becoming Executive Editor, then Editor-in-Chief a position he held until January 2020. Shortly thereafter he joined Third Door Media as Editorial Director at MarTech.
Kim was Associate Editor at a New York Times hyper-local news site, The Local: East Village, and has previously worked as an editor of an academic publication, and as a music journalist. He has written hundreds of New York restaurant reviews for a personal blog, and has been an occasional guest contributor to Eater.
Add us as a preferred source on Google
Google's "preferred sources" feature allows users to customize their search results by selecting news outlets they want to see more often in the "Top Stories" section.
Add Martech NowRelated Articles

Firsthand expertise, original research, and transparent thinking carry more weight than polished messaging. Here's why.
Read More
Cost savings are only the beginning. Learn how organizations move from AI-driven efficiency to entirely new sources of growth.
Read More
Marketing artificial intelligence (AI)
6 minutes readSEO's history offers clues about which GEO tactics may endure, which may disappear, and why sustainable approaches matter most.
Read More
Marketing artificial intelligence (AI)
5 minutes readYour AI tools may be doing exactly what you asked. That doesn't mean they're doing what the business needs.
Read MoreRelated Articles
Firsthand expertise, original research, and transparent thinking carry more weight than polished messaging. Here's why.
Read More
Cost savings are only the beginning. Learn how organizations move from AI-driven efficiency to entirely new sources of growth.
Read More
Marketing artificial intelligence (AI)
6 minutes readSEO's history offers clues about which GEO tactics may endure, which may disappear, and why sustainable approaches matter most.
Read More
Marketing artificial intelligence (AI)
5 minutes readYour AI tools may be doing exactly what you asked. That doesn't mean they're doing what the business needs.
Read More