How to create your own digital newsroom
Looking to create a way to effectively monitor real-time news in your industry? Columnist Andrew Ruegger shows you how to consolidate real-time information on publishers, publications and social trends to bring you the insights you need.
Spy on Any Website

There has always been a high demand from companies, both big and small, to understand the breaking news in relevant industries and how it impacts them. The internet has revolutionized companies’ and individuals’ ability to get news, and it has dramatically increased the volume of publishers and publications.
Publisher and article relevancy has become more difficult to define because of the overwhelming availability of information. For example, 50 years ago, if your company produced $100 million building management systems and wasn’t mentioned in The New York Times, it may have been because you weren’t relevant. But now, it’s more likely that the Times is just allocating resources to produce articles on Donald Trump.
This publication strategy makes sense, as 318 million people in the US should care about the presidential election, while building management systems may only interest 100,000 people.
So how do you make a relevant digital newsroom for your industry? I’ll show you.
What is a digital newsroom?
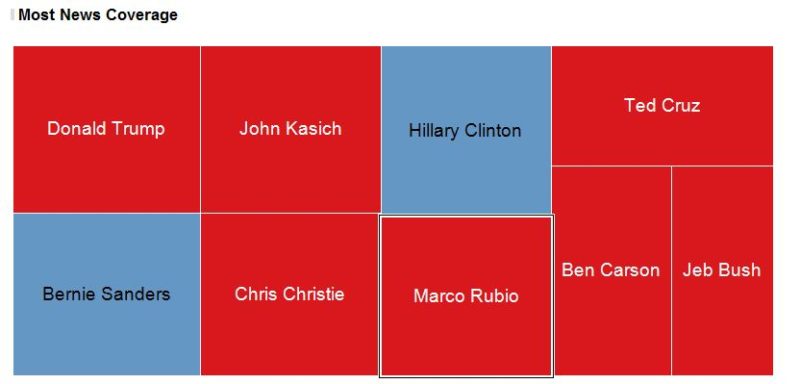
I define the “digital newsroom” as a consolidation of real-time information that showcases relevant publisher, publication and social trends that offer insights into the digital landscape. The example below highlights news on presidential candidates and can be replicated by following the steps I’ll outline in this article.

[click to enlarge]
Digital newsroom checklist
Here is a basic list of what you will need:
- A Gmail account: https://accounts.google.com/SignUp
- A Twitter account: https://twitter.com/signup?lang=en
- A Twitter application API key: https://apps.twitter.com/
- KNIME: https://www.knime.org/downloads/overview
- To visualize my news in this example, I use TIBCO Spotfire. Tableau also works. Or it can all be done in KNIME. (Spotfire and Tableau are not free.)
Recommended Articles


Getting relevant real-time news
When building your own newsroom, you will use keywords, people, products and brands relevant to your business.
Your first destination is Google Alerts, which can be generated once you have a Gmail account:
https://www.google.com/alerts#
For those of you who aren’t familiar with them, Google Alerts are notifications of any type of digital asset publication (e.g., image, article or video) related to your specified term. You will want to set one up for all relevant terms and topics with the following settings:
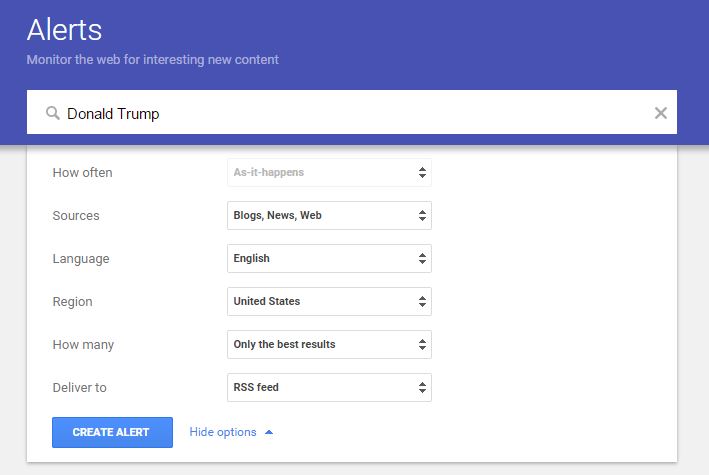
Continue adding content until you have a full collection:
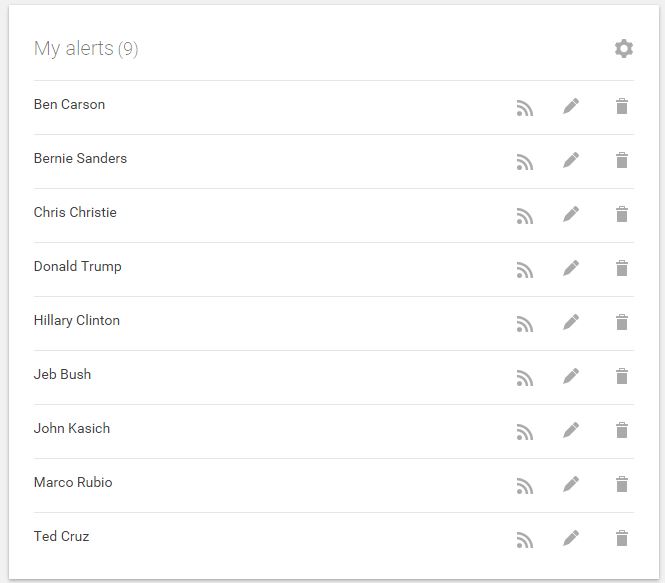
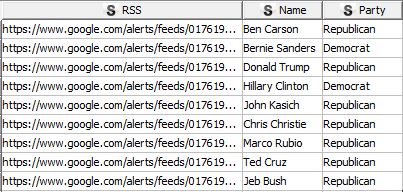
Now, select the RSS feed icon, and copy and paste all of the RSS feed URLs into a table in KNIME (or Excel and put into KNIME later):

Getting access to Twitter data
Your next stop is to obtain a Twitter API key so you can get social conversation. (If you already have one, skip ahead to the next section.)
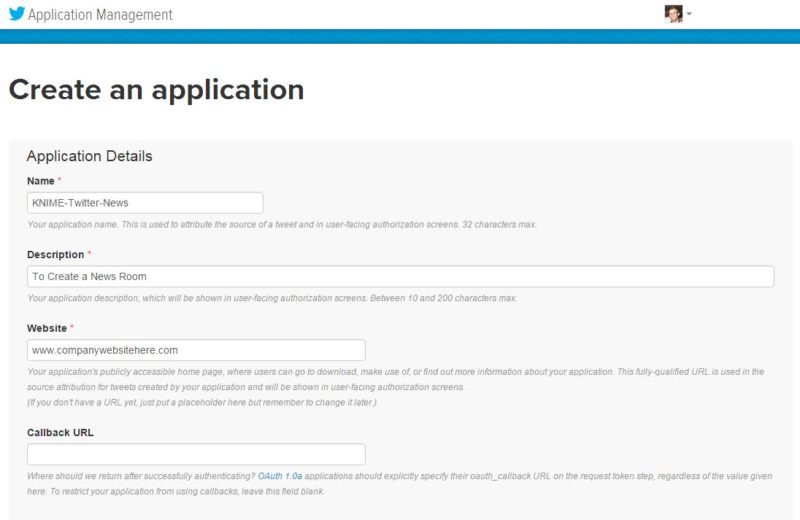
Select Create New App:

Fill out application information, and read terms and conditions. Put any website that is live that you have affiliation with. And if you are not affiliated with any, you can make one up (but don’t tell). The format of the site must be: http://www.companywebsitehere.com — having both http and www.
Agree and create your Twitter application:

You may need to add your mobile phone to ensure people aren’t collecting hundreds of API keys and rotating them… not that I know anyone who does that. When you succeed, it will look like this:

Select Keys and Access Tokens, followed by Create Access Token at the bottom of the page. You will need the four codes present in this tab to collect information from the Twitter API, so save them somewhere easy to find. The fields are:
- Consumer Key (API KEY)
- Consumer Secret (API Secret)
- Access Token
- Access Token Secret
Now that we have all the sources of information, we just need to collect, store and visualize. Thankfully, this is relatively straightforward in the KNIME environment.
KNIME will enable you to do a lot of developer-like work without a developer on staff. It is a free, open-source visual programming language. For these two reasons, I often use it in examples, so if any reader would like to replicate the work, there is not necessarily a cost to do so.
Collecting, storing and viewing your news
You will get updates from the RSS feeds you created through Google Alerts any time content is published that Google indexes, which is especially quick for news. With your Twitter API key, you can get information on the same terms from Twitter at a frequency within the limits of your rate allowance, which for tweets is ~18,000–45,000 per 15 minutes.
The workflow looks like this for RSS article collection:

[click to enlarge]
The HTTP retriever gets the status and result of the XML RSS feed, and then the feed parser turns the feeds into something that is easier to read. HTML elements occasionally slip through, so some cleaning is required with regular expression (regex) rules, and the joiner node makes it so the rest of the data associated with your initial terms are carried along.
Your data should look something like this:

[click to enlarge]
With the flow shown below, after the information is collected, the database connection is activated, and the destination table is read — the pre-existing table is referenced against new publications passed through the RSS feeds, so that if duplicate entries do exist, they are excluded, and only new ones are written onto the database:
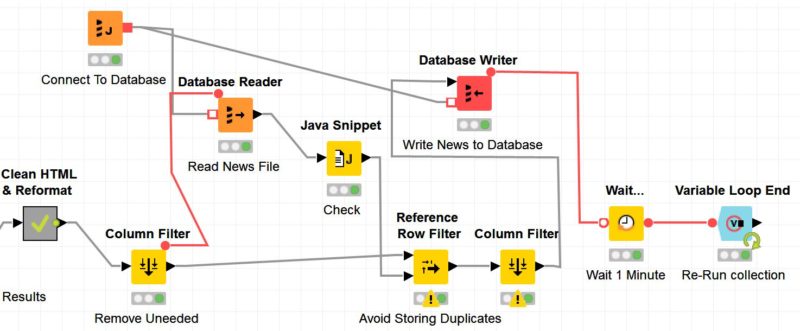
After the Database Writer, a variable flow passes to the wait node, which allows you to select a stall time before ending the workflow. When the process reaches the end, it will rerun again because of the closed loop (Counting Loop Start + Variable Loop End).
In this case, I set my wait node to one minute, so that every minute in the KNIME workflow run, I check my RSS feeds and my database table and add any new publications. This will then render in my Spotfire dashboard, which is also set to check the data source and refresh every minute.
Note: More efficient methods of avoiding duplicate collections will likely be needed with large data sets.
Additionally, if you set the Wait Node to wait one minute and rerun, you will essentially need 3,600 loops to cover a full day.
The overall workflow process is similar to collecting social mentions, except for authenticating with Twitter’s API (which is the reason we obtained a token beforehand).
The flow will look something like this:

[click to enlarge]
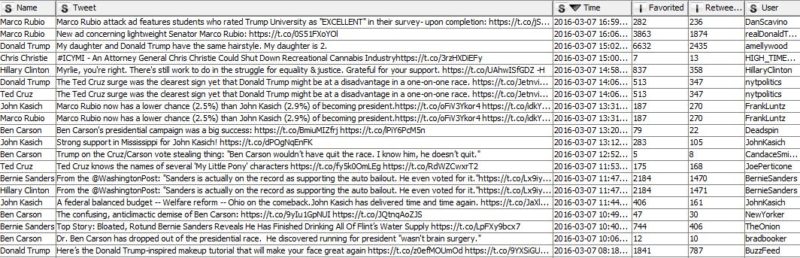
And your data will look like this (depending on query selection in the Twitter Search node):
[click to enlarge]
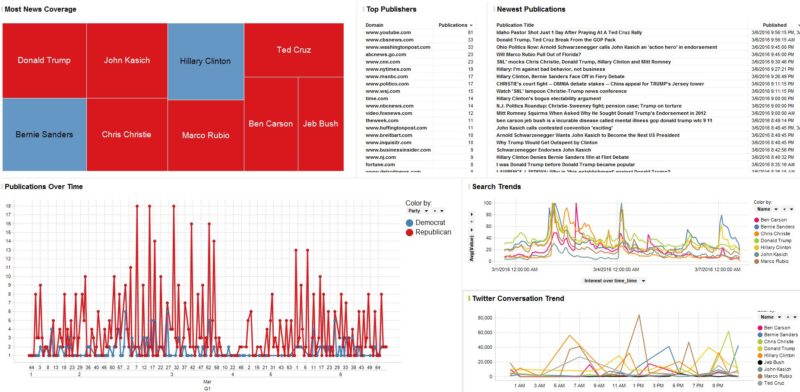
Overall newsroom:
[click to enlarge]
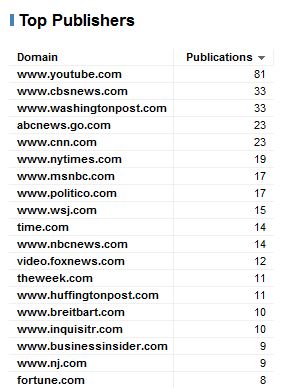
Aggregate sum of publications by publisher:
Newest publications:

Publications over time by second:

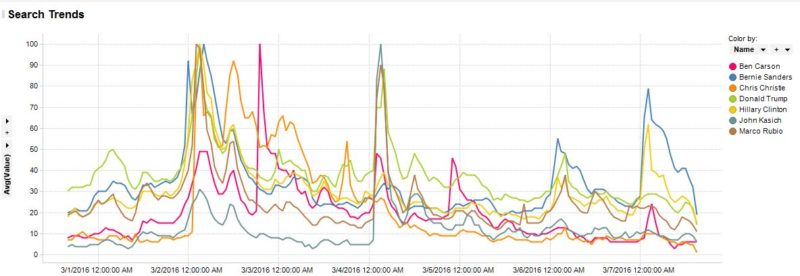
Search trends by hour colored by candidate:
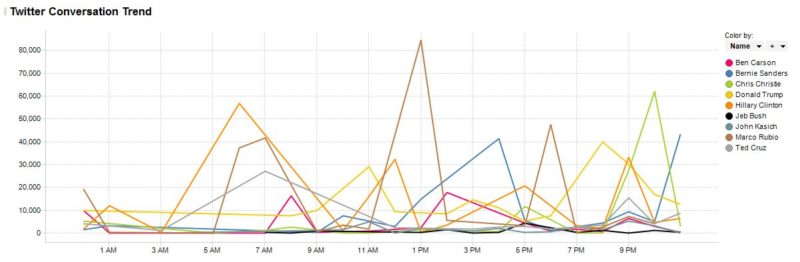
Twitter non-re-tweet mentions in the US by candidate by hour:
The major barrier to creating a real-time news monitoring environment tends to be the ability to collect, manipulate, aggregate and properly store information on a scheduled basis. But once the the collection and storage process is set, there are countless ways to play with and visualize each data source, especially when looking at social media information (e.g., top influencer by retweets, likes, volume or location).
I hope this how-to article at least helped get the juices flowing. I realize those unfamiliar with KNIME or another visual programming application may have struggled with the mess of connected squares, but it’s important to stress that with a little ingenuity, there are free methods to get a lot of the information you need.
Typically, when I create this type of environment for clients, I have the good fortune of working with a lot of proprietary technology and data partners to provide real-time information on every digital channel. But it’s important to remember that the information management logic is relatively the same, regardless of the number of sources or volume of the data. So once you learn the basics, you can expand what you’re collecting and analyzing.
Here is a link to download the RSS workflow. I will be doing an in-depth follow-up on knime.org/blog for those who are interested in learning more. This also will include how I got real-time search trends, which I apologize isn’t included in the how-to but was included in the visual. Unfortunately, it’s very technical and requires at least a basic understanding of Java.
Contributing authors are invited to create content for MarTech and are chosen for their expertise and contribution to the martech community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. MarTech is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.
Andrew Ruegger is Senior Partner, Head of Data Science at GroupM Search & Social - Catalyst. He is a digital veteran with over 7 years of experience in advertising. He currently is responsible for running the data and insights practice for search and social marketing.
View Author ProfileAdd us as a preferred source on Google
Google's "preferred sources" feature allows users to customize their search results by selecting news outlets they want to see more often in the "Top Stories" section.
Add Martech NowRelated Articles

Turn AI-generated code into maintainable software with a prompt log that improves governance and accountability.
Read More
Good martech tools can't deliver value without ownership, governance, and the operational discipline to keep them working together.
Read More
Use AI to eliminate busywork and uncover better account insights so your team can spend more time building the relationships that win deals.
Read More
The missing link between awareness and trust may explain why higher acquisition costs aren't producing better business outcomes.
Read MoreRelated Articles
Turn AI-generated code into maintainable software with a prompt log that improves governance and accountability.
Read More
Good martech tools can't deliver value without ownership, governance, and the operational discipline to keep them working together.
Read More
Use AI to eliminate busywork and uncover better account insights so your team can spend more time building the relationships that win deals.
Read More
The missing link between awareness and trust may explain why higher acquisition costs aren't producing better business outcomes.
Read More