3 case studies of duplicate content consolidation
Columnist Chris Long shares examples of how he addressed duplicate and similar website content to improve organic search performance for his clients.
It’s commonly held that duplicate or substantially similar content is bad for SEO. When Google finds duplicate content, this creates a conflict for the algorithm. Essentially, Google gets confused as to which page should be the primary ranking URL for a given search query, so it chooses the one it believes to be the most relevant. Unfortunately, the URL it chooses may not be the one you wish to display — and, in cases of exact duplicate content, the other versions of the page may even be filtered out of search results.
The best way to fix this issue is to consolidate the duplicate/similar content’s ranking signals into a singular version of the page. In practice, this is usually done by implementing either a 301 redirect, canonical or “noindex” tag.
While many of us know this to be true, it can often be helpful to see examples of the different types of duplicate content that exist in the wild and how to best handle them. To better help you find and fix duplicate/similar content, I’ve provided case studies for three different instances where we consolidated these types of pages and noted the results we saw.
1. Consolidating exact duplicate pages
The simplest type of duplicate content issue you may encounter is a straightforward duplicate page. This page will contain the exact same content as another page on the website. For one of our clients that advertises franchise listings, we found two pages that contained the exact same content targeted towards “low-cost franchises.” You can see that the two pages were identical here:

Because there was no need for both of these pages, we suggested that our client 301 redirect one of them to the other page. Personally, I love using 301 redirects if possible because it points both users and link equity to a single URL. It tends to send a stronger signal than the other consolidation methods. Almost immediately, we saw rankings and traffic to the original page spike.
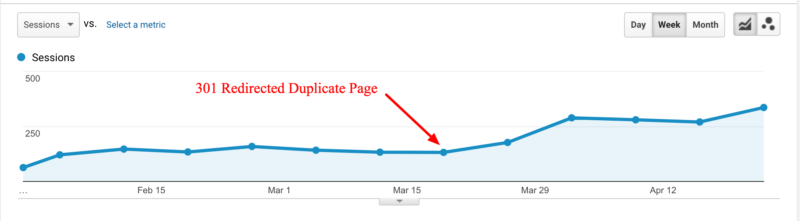
Since the 301 redirect was implemented, organic traffic improved by over 200 percent to the page, and it is now consistently one of the top three pages on the site each month.
How did we decide which page to 301 redirect? To do this, we took a look at three different factors:
- Which page the site internally linked to the most.
- Which page was currently ranking the best.
- Which page had the most organic traffic historically.
The final destination page we selected had the most internal links and traffic and was also ranking ahead of the other. I would definitely urge you to look at these three factors when deciding which page to consolidate your duplicate pages to.
2. Consolidating semantically similar pages
As Google gets better and better at understanding semantically related topics, the search engine is starting to return more results that contain topics outside of the initial query. For instance, in a search for “braces near me,” I see a lot of results for orthodontists, even though the term “orthodontist” wasn’t in my original search. Google is most likely doing this type of consolidation for some of your core keywords, and you should be aware of what it’s grouping together.
The client mentioned above has done a good job of building out landing pages that target different industry options (Auto Franchises, Cleaning Franchises and so on). This included the following two pages: Food Franchises and Fast Food Franchises.
At first glance, it might seem obvious that searches for these two terms might yield different results. However, we were seeing that Google was treating these terms somewhat interchangeably:

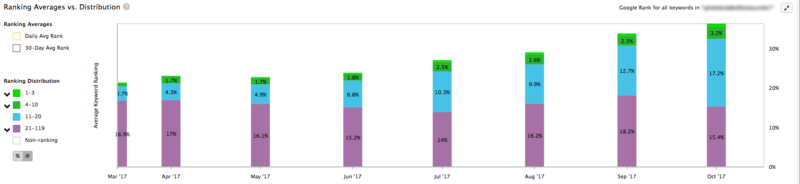
It appeared that Google had collected enough user data to determine that searchers wanted similar results for these two queries. Because neither of their pages were ranking well at the time, and they both contained very similar content, we recommended that they consolidate the ranking signals.
Our client still wanted users to be able to access both pages, so we recommended they implement a canonical tag instead of a 301 redirect. They added the canonical tag on the “Fast Food” page that pointed to the “Food” page because the latter gave users a list of all the franchises under both categories.
Once again, the results were pretty convincing:

Organic traffic to the page has improved by 47 percent since implementation. This shows us that it’s important to not only consolidate pages where standard keyword targeting and content overlap, but also where there might be conflict with other semantically related pages.
3. Consolidating URL parameters
Last but certainly not least is looking for URL parameters that Google may be finding and assessing as duplicates of other pages. While it’s not always the case, often URLs with parameters appended to them will contain duplicate or very similar content to the source page.
This was certainly the situation for another one of our clients. We found that many of their key pages were generating a large number of URLs with different parameters. While these pages did contain slightly different content, to the search engines they appeared to be largely the same.
We solved this issue by using a canonical tag. We instructed the client to dynamically implement canonical tags that would reference the primary landing pages that Google should be ranking. As Google slowly removed these URL parameters from the index, we began to see a large shift in rankings.
Organic traffic followed suit, and the website now generates over 800 percent more than our baseline levels.
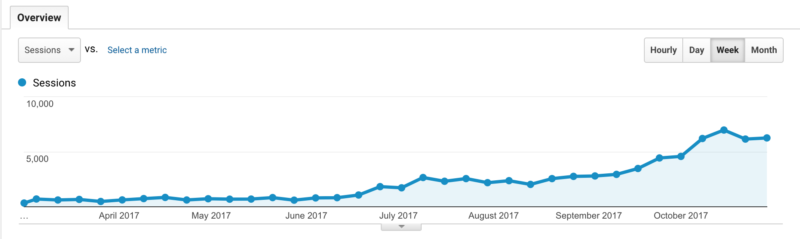
While we have been working on many other aspects of the site, there’s no doubt in my mind that this was a major factor in the ranking and traffic increases we’ve seen.
Finding consolidation opportunities
All of this begs the question: How do you find instances of duplicate or similar content that can be consolidated?
While there are many different tools out there that can help you with this, I’ve found no substitute to looking manually. When evaluating if duplicate/similar content is a potential problem, I start with a “site:” search of that domain followed by their core keywords. If I see pages with similar meta data in Google’s index, this is a red flag that they may be duplicates:
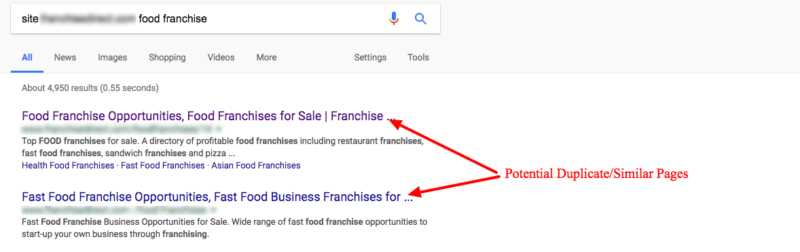
I repeat this process for as many keywords as necessary until I have a good understanding of the problem.
I highly recommend researching duplicate content issues manually to completely understand the nature of the problem and the best way to address it. Doing so can lead to massive improvements for the organic search performance of an individual page, or even an entire website.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author